How to Scrape and Download All PDF Files on a Website

There might be scenarios where you might have to download a long list of PDF files from a website.
If the number of files is large enough, you might be interested in automating the process.
In this updated guide, we will use a free web scraper to scrape a list of PDF files from a website and download them all to your drive.
Scraping a list of PDF Files
First, we’ll need to set up our web scraping project. For this, we will use ParseHub, a free and powerful web scraper that can scrape any website.
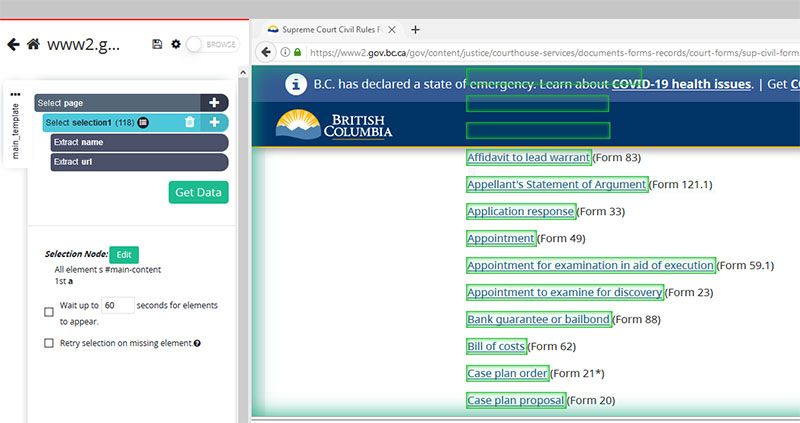
For this example, we will use the Province of British Columbia’s webpage for “Supreme Court Civil Rules Forms”. This page has a large list of links to PDF files.
We will use our scraper to extract the links to all these files and download them on to our Dropbox account.
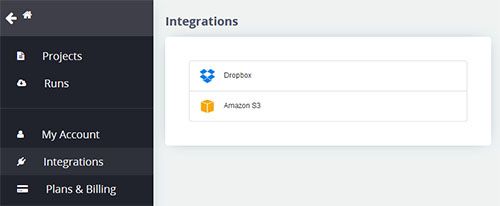 Integrating with dropbox " />
Integrating with dropbox " />
- Click on the Dropbox option.
- Enable the Integration.
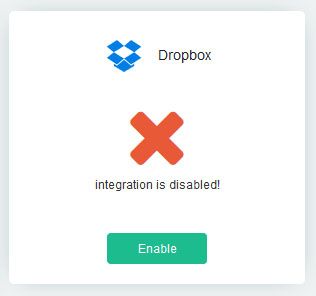 enabling integration with dropbox" />
enabling integration with dropbox" />
- You will be asked to login in to Dropbox. Login and allow ParseHub access. Your integration will now be enabled in ParseHub.

Setting up the web scraper
- Now, go back to ParseHub’s new main menu and click on “New Project”
- Enter the URL for the page you want to scrape. ParseHub will now load this page inside the app and let you make your first selection.
- Scroll to the first link in the page and click on it to select it. The link will be highlighted in Green to indicate that it has been selected. The rest of the links will be highlighted in Yellow.
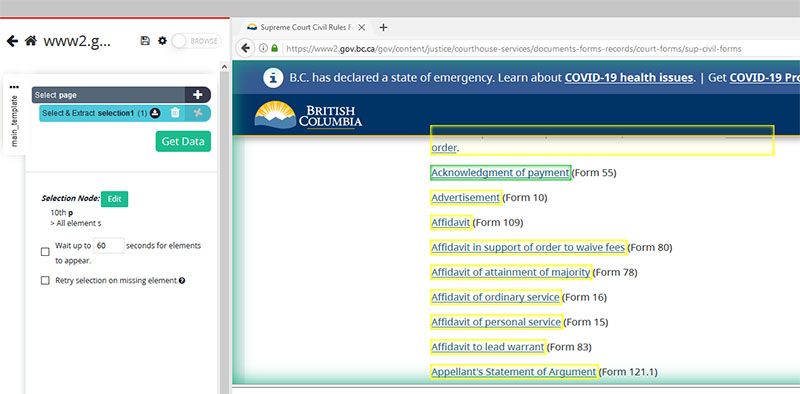
- Click on the second link in the list. All the links will now be highlighted Green to indicate they have been selected.
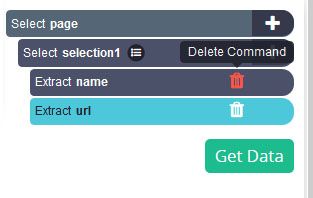
- In the left sidebar, we will get rid of the “name” extraction. As we are not interested in extracting the names of the links.
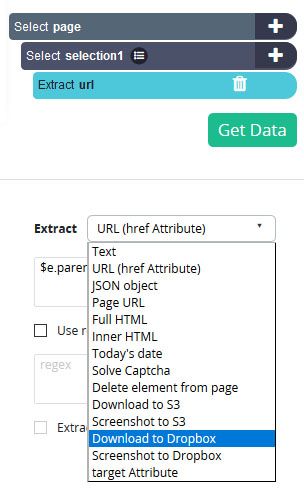
- Now, click on the Extract URL command and open up the Extract dropdown under it. From the dropdown, choose the Download to Dropbox option.
Running your scrape
Now it’s time to run your scrape and have all your files downloaded directly into your Dropbox.
- On the left sidebar, click on the green Get Data button.
- You can now test, schedule or run your scrape. In this case, we will run our scrape right away.

- The scraper will now run and automatically add all the PDF files to your Dropbox. If you’ve synced your Dropbox to your PC or Mac, all files will be downloaded to your file system as well.
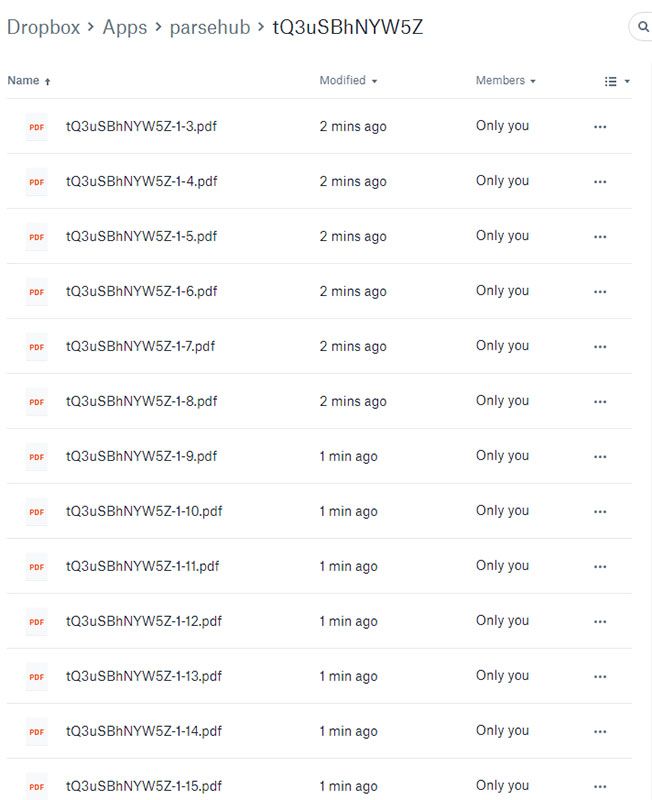
Downloading all PDF Files in a website
You have now successfully scraped and downloaded all PDF files in a website with the help of a free web scraper!
If you run into any issues through this process, don’t hesitate to contact us via the live chat on our website or through support@parsehub.com.

Martin Perez
Martin is the Digital Marketing Specialist at ParseHub. A lover of all things related to tech, culture, and the internet.
